ЖўЁЂШЫЪБЕФМЦЫу
ШЫЪБ(person-time, PT):ЙлВьШЫЪ§ГЫвдЫцЗУЕЅЮЛЪБМфЕФЛ§ЃЌЪБМфЕЅЮЛГЃгУФъЃЌ
вЛЖЈЕФШЫЪБЃЈШЫФъЃЉЪ§ПЩРДздВЛЭЌЕФШЫЪ§гыВЛЭЌЕФЙлВьЪБМф
МЦЫуЗНЗЈ—— вдИіШЫЮЊЕЅЮЛМЦЫуБЉТЖШЫФъЃЈОЋШЗЗЈЃЉЁЂгУНќЫЦЗЈМЦЫуБЉТЖШЫФъгУЪйУќБэЗЈМЦЫуШЫФъ
Ш§ЁЂТЪЕФМЦЫу
ЃЈвЛЃЉГЃгУжИБъ
1ЁЂРлЛ§ЗЂВЁТЪЃЈcumulative incidenceЃЌCIЃЉ
ЬѕМўЃКЙлВьШЫЪ§БШНЯЖрЃЌШЫПкБШНЯЮШЖЈ
ЪЕжЪЃКвЛжж“ОВЬЌТЪ” ШЁжЕЃК0ЁЋ1
РлЛ§ЗЂВЁТЪЃН ећИіЙлВьЦкФкЕФЗЂВЁШЫ Ъ§/ЙлВьПЊЪМЪБЕФШЫПкЪ§
2ЁЂЗЂВЁУмЖШЃЈincidence densityЃЌIDЃЉ
ЬѕМўЃКбаОПЖдЯѓНјШыЖгСаЕФЪБМфВЛвЛ
МШЫЕУїСЫИУШЫШКЗЂЩњЕФаТВЁР§Ъ§ЃЌгжЫЕУїИУШЫШКДѓаЁКЭЗЂЩњетаЉР§Ъ§ОРњЕФЪБМф
ЪЕжЪЃКвЛжж“ЖЏЬЌТЪ”ЃЌДјгаЫВЪБЦЕТЪаджЪ ШЁжЕЃК0ЁЋ
3ЁЂБъЛЏБШ
ЗЂВЁУмЖШЃНЙлВьЦкМфЗЂВЁЕФШЫЪ§/ЙлВьЖдЯѓЕФШЫЪБЪ§
ЬѕМўЃКбаОПЖдЯѓЪ§ФПБШНЯЩйЃЌНсОжЪТМўЕФЗЂЩњТЪБШНЯЕЭ
дРэЃКвдШЋШЫПкЗЂВЁЃЈЫРЭіЃЉТЪзіЮЊБъзМЃЌЫуГіИУЙлВьШЫШКЕФРэТлЗЂВЁЃЈЫРЭіЃЉ ШЫЪ§ЃЌМДдЄЦкЗЂВЁЃЈЫРЭіЃЉШЫЪ§ЃЌдйЧѓЙлВьШЫШКжаЪЕМЪЗЂВЁЃЈЫРЭіЃЉШЫЪ§гыДЫдЄЦкЗЂВЁШЫЪ§жЎБШЃЌМДЕУБъЛЏЗЂВЁЃЈЫРЭіЃЉБШ
ЗжРр——БъЛЏЫРЭіБШЁЂБъЛЏБШР§ЫРЭіБШ
БъЛЏЫРЭіБШЃЈSMRЃЉ
SMR = баОПШЫШКжаЙлВьЫРЭіЪ§/БъзМШЫПкЃЈШЋШЫПкЃЉдЄЦкЫРЭіЪ§
SMR>1ЃЌЫЕУїБЉТЖЕМжТЛђДйНјСЫНсОжЕФЗЂЩњ
SMR<1ЃЌЫЕУїБЉТЖдЄЗРЛђМѕЩйСЫНсОжЕФЗЂЩњ
SMR=1ЃЌЫЕУїБЉТЖгыМВВЁУЛгаЙиЯЕБъЛЏБШР§ЫРЭіБШЃЈSPMRЃЉ
ЬѕМўЃКВЛжЊЕРФГжжМВВЁЕФЫРЭіТЪЃЌжЛжЊЕРФГВЁЕФЫРвђЙЙГЩ

RR гы AR ЧјБ№ЃП
СЊЯЕЃКЖМЪЧБэЪОЙиСЊЧПЖШЕФживЊжИБъ
ЙЋЙВЮРЩњвтвхВювьЃК
RR ЫЕУїБЉТЖепгыЗЧБЉТЖепБШНЯдіМгЯргІМВВЁЮЃЯеЕФБЖЪ§ЃЌОпгаВЁвђбЇЕФвтвх
AR дђвЛАуЪЧЖдШЫШКЖјбдЃЌБЉТЖШЫШКгыЗЧБЉТЖШЫШКБШНЯЃЌЫљдіМгЕФМВВЁЗЂЩњЪ§СПЃЌШчЙћБЉТЖвђЫиЯћГ§ЃЌОЭПЩМѕЩйетИіЪ§СПЕФМВВЁЗЂЩњЃЌОпгаМВВЁдЄЗРКЭЙЋ ЙВЮРЩњбЇЩЯЕФвтвх
ЙщвђЮЃЯеЖШАйЗжБШЃЈARЃЅЃЉ
гжГЦЮЊВЁвђЗжжЕ EFЃЈetiologic fractionЃЉЃЌЪЧжИБЉТЖШЫШКжаЕФЗЂВЁЛђЫРЭіЙщвђгкБЉТЖЕФВПЗжеМШЋВПЗЂВЁЛђЫРЭіЕФАйЗжБШЁЃ

ЕкЮхНк ЖгСабаОПЕФЦЋваМАЦфЗРжЙ
вЛЁЂГЃМћЦЋваЕФжжРр
бЁдёЦЋваЁЂЪЇЗУЦЋваЁЂаХЯЂЦЋваЁЂЛьдгЦЋвабЁдёЦЋваЃЈselection biasЃЉ
ЪЕжЪЃКбаОПШЫШКЃЈбљБОЃЉВЛЪЧвЛАуШЫШКЃЈзмЬхЃЉЕФвЛИіЮоЦЋЕФДњБэ
бЁЖЈЕФЖдЯѓОмОјВЮМгЁЂзЪСЯВЛШЋЁЂбаОПЖдЯѓгЩзддИепзщГЩЁЂдчЦкЛђЧБЗќЦкВЁШЫ бЁдёЦЋваЕФдЄЗР
е§ШЗЕФГщбљЗНЗЈЁЂБШНЯжОдИепгые§ГЃбЁдёВЮМгЕФШЫШКЃЌВювьаЁЪБЃЌПЩПМТЧВЮМг
бЯИёАДЙцЖЈЕФБъзМбЁШЁЖдЯѓЁЂЖдбаОПЖдЯѓМсГжЫцЗУЕНЕз ЪЇЗУЦЋва lost to follow-up
ЪЕжЪЃКбЁдёЦЋваЕФвЛжжЁЃЧЈвЦЁЂЭтГіЁЂВЛдИМЬајКЯзїЖјЭЫГіЃЛЫРгкЗЧжеЕуМВВЁ
ЙРМЦ—— БШНЯСНзщЪЇЗУТЪЕФВюБ№МАВЛЭЌГЬЖШБЉТЖзщЪЇЗУТЪЕФВюБ№ЪЇЗУШЫШКгыЫцЗУЕНЕФШЫШКЕФФГаЉЛљБОЬиеїгаЮоВюБ№
СЫНтЪЇЗУепзюКѓНсОжгыБЛЫцЗУЕНШЫШКЕФНсОжБШНЯвдЭЦВтЪЇЗУЕФгАЯь ЪЇЗУЦЋваЕФдЄЗР
ЬсИпбаОПЖдЯѓЕФвРДгадЃЌдкбЁдёЖдЯѓЪБбЁдёЗћКЯЬѕМўЧввРДгадКУЕФбаОПЖдЯѓ
ЧАЦкЕФаћДЋЙЄзїаХЯЂЦЋва
дкЛёШЁБЉТЖЁЂНсОжЛђЦфЫћаХЯЂЪБЫљГіЯжЕФЯЕЭГЮѓВюЛђЦЋВюНааХЯЂЦЋваЁЃаХЯЂЦЋвагжГЦЮЊДэЗжЦЋваЃЈmisclassification biasЃЉ
РДдДЃКбаОПепЁЂЕїВщЖдЯѓЁЂВтСПЙЄОпЁЂдЪММЧТМВЛзМ
аХЯЂЦЋваЃКЭЌЕШЗЂЩњгкБЉТЖзщКЭЗЧБЉТЖзщЃЗЧЬивьадДэЗжЃRR→1
аХЯЂЦЋваЃКВЛЭЌЕШЗЂЩњгкБЉТЖзщКЭЗЧБЉТЖзщЃЬивьадДэЗжЃRR ЛђИпЛђЕЭаХЯЂЦЋваЕФдЄЗР
баОПепЛђЕїВщепЃКЭЌЕШЖдД§УПИібаОПЖдЯѓ
ЕїВщЖдЯѓЃКЪЕЪТЧѓЪЧ
ВтСПЙЄОпЃКаЃзМЛьдгЦЋва
БЉТЖвђЫигыМВВЁЗЂЩњЕФЯрЙиЃЈЙиСЊЃЉГЬЖШЪмЕНЦфЫћвђЫиЕФЭсЧњЛђИЩШХ
адБ№ЁЂФъСфЪЧзюГЃМћЕФЛьдгвђЫи
ТњзуЬѕМў
БиаыгыЫљбаОПМВВЁЕФЗЂЩњгаЙиЃЌЪЧИУМВВЁЕФЮЃЯевђЫижЎвЛ
БиаыгыЫљбаОПвђЫигаЙи
БиаыВЛЪЧбаОПвђЫигыМВВЁВЁвђСДЩЯЕФжаМфЛЗНкЛђжаМфВНжш ЛьдгЦЋваЕФдЄЗР
ЩшМЦНзЖЮЃКЯожЦ
ЖдеебЁдёЃКЦЅХф
ГщШЁЖдЯѓЃКЫцЛњЛЏ
ДІРэЃКЗжВуЗжЮіЁЂБъзМЛЏЛђЖрвђЫиЗжЮіЕФЗНЗЈ
ЧАЬсЃКбаОПепвЊгаФмСІЪЖБ№ЛьдгзїгУЕФДцдк
ЕкЮхеТ ВЁР§ЖдеебаОП Case-Control Study
ЕквЛНк ВЁР§ЖдеебаОПЕФЛљБОдРэ
вдЯждкШЗеяЕФЛМгаФГЬиЖЈМВВЁ(МДЕБЧАбаОПжаДђЫубаОПЕФМВВЁ)ЕФВЁШЫзїЮЊВЁР§ЃЌвдВЛЛМгаИУВЁЕЋ ОпгаПЩБШадИіЬхзїЮЊЖдее(СєвтЧјЗж Ек 4 еТ ЖгСабаОП баОПЖдЯѓ)ЃЌЭЈЙ§бЏЮЪЁЂЪЕбщЪвМьВщЛђИДВщВЁЪЗЃЌЫбМЏИїжжПЩФмЕФЮЃЯевђЫиЕФБЉТЖЪЗ(БЉТЖЃКНгДЅЙ§ФГаЉЮяжЪЁЂОпБИФГЬиеїЁЂ ДІгкФГзДЬЌ БЉТЖЃКгаКІЕФЁЂгавцЕФ)ЃЌВтСПВЂБШНЯВЁР§зщгыЖдеезщжаИївђЫиЕФБЉТЖБШР§(Сєвт ЖгСабаОП БЉТЖгыЗЧБЉТЖзщЕФМВВЁБШР§)ЃЌОЭГМЦбЇМьбщ(зюГЃгУЕФОЭЪЧc2 Мьбщ)ЃЌШєСНзщВюБ№гавтвхЃЌдђПЩШЯЮЊБЉТЖвђЫигыМВВЁжЎМфДцдкзХЭГМЦбЇЩЯЕФЙиСЊ(СєвтЧјЗж Ек 4 еТ ЖгСабаОП жБНгвђЙћЙиСЊ)ЁЃдкЦРЙРСЫИїжжЦЋва(ЦЋваЛсгАЯьНсЙћецЪЕад)ЖдбаОПНсЙћЕФгАЯьКѓЃЌ дйНшжњВЁвђЭЦЖЯММЪѕ(ВЮПМ Ек 8 еТ баОПЕФецЪЕадгывђЙћЭЦЖЯ)ЃЌЭЦЖЯГіФГИіЛђФГаЉБЉТЖвђЫи (БЉТЖвђЫиЃКЮЃЯевђЫи БЃЛЄвђЫи)ЪЧМВВЁЕФЮЃЯевђЫиЃЌДгЖјДяЕНЬНЫїКЭМьбщВЁвђМйЫЕЕФФПЕФЁЃ ВЁР§ЖдеебаОПЕФЬиЕу
—— ЪєгкЙлВьЗЈЃЛЩшСЂЖдеезщЃЛгЩ“Йћ”МА“вђ”: МВВЁ→БЉТЖЃЛЬНЫїЁЂМьбщВЁвђМйЫЕ
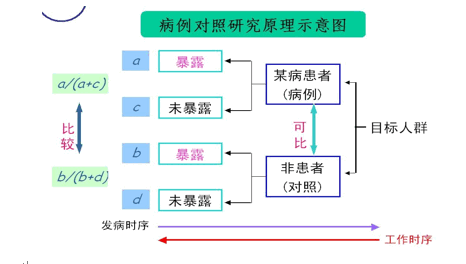
ЕкЖўНк ВЁР§ЖдеебаОПЕФРраЭ
ВЁР§гыЖдееВЛЦЅХф
ВЁР§гыЖдееЦЅХф——ЦЕЪ§ЦЅХфЁЂИіЬхЦЅХф
ВЁР§ЖдеебаОПЕФбмЩњРраЭ
ГВЪНВЁР§ЖдеебаОПЁЂВЁР§-ЖгСабаОПЁЂВЁР§НЛВцбаОПЁЂ
ЕЅДПВЁР§баОПЁЂВЁР§-ЪБМф-ЖдееЩшМЦ
ВЁР§гыЖдееЦЅХфЕФвђЫи——ЛьдгвђЫи(вбжЊЁЂПЩвЩ)ЃЛИДКЯвђЫи(ФъСф + адБ№)ВЛФмЦЅХфЕФвђЫи
БиаыЪЧЛьдгвђЫи
ВЁР§гыЖдееЦЅХфЕФФПЕФ——ЬсИпбаОП(ЭГМЦ)аЇТЪ[баОПаЇТЪЃНR/(R+1)]ЁЂПижЦЛьдгвђЫизїгУЦЅХфДјРДЕФЮЪЬт——діМгЙЄзїФбЖШ(ЗбгУЁЂЪБМф)ЃЛЯожЦбљБОСПЃЛЦЅХфвђЫиНЋЮоЗЈдйНјааЗжЮіЦЅХфЙ§ЭЗovermatching:АбВЛБивЊЕФЯюФПСаШыЦЅХфЃЌЦѓЭМЪЙВЁР§гыЖдееОЁСПвЛжТЃЌОЭПЩФм
ЭНШЛЖЊЪЇаХЯЂЃЌдіМгЙЄзїФбЖШЃЌНсЙћЗДЖјНЕЕЭСЫЙЄзїаЇТЪЃЌетжжЧщПіГЦЮЊЦЅХфЙ§ЭЗЁЃ
ГВЪНВЁР§ЖдеебаОПnested case-control study
НЋДЋЭГЕФБјСІЖдеебаОПКЭЖгСабаОПЕФвЛаЉвЊЫиНјаазщКЯКѓаЮГЩЕФвЛжжбаОПЗНЗЈЃЌвВОЭ ЪЧдкЖдвЛИіЪЕЯжШЗЖЈКУЕФЖгСаНјааЫцЗУЙлВьЕФЛљДЁЩЯЃЌдйгІгУВЁР§ЖдеебаОП(жївЊЪЧЦЅ ХфВЁР§ЖдеебаОП)ЕФЩшМЦЫМТЗНјаабаОПЗжЮі
ЕкЫФНк ВЁР§ЖдеебаОПЕФЪЕЪЉ
ВЁР§ЖдеебаОПЕФвЛАуВНжш
ЬсГіМйЩш жЦЖЈбаОПМЦЛЎ ЪеМЏзЪСЯ ЖдЪеМЏЕФзЪСЯНјааећРэгыЗжЮізмНсВЂЬсГібаОПБЈИц
ВЁР§ЖдеебаОПЕФЪЕЪЉ
ЬсГіМйЩш УїШЗбаОПФПЕФЃЌбЁдёЪЪвЫЕФЖдееаЮЪН ВЁР§гыЖдееЕФРДдДгыбЁдёбљБОКЌСПЕФМЦЫуЛёШЁбаОПвђЫиЕФаХЯЂ зЪСЯЕФЪеМЏ
ЃЈШ§ЃЉВЁР§гыЖдееЕФРДдДгыбЁдё
ВЁР§гыЖдееЕФЛљБОРДдД——вдвНдКЮЊЛљДЁ hospital-basedЃЛвдЩчЧјЮЊЛљ community-based

1ЁЂВЁР§ЕФбЁдё
аТЗЂВЁР§ЃКЬсЙЉЕФаХЯЂНЯЮЊПЩПП
ЯжЛМВЁР§ЃКВєШыМВВЁЧЈбгМАДцЛювђЫидкФк
ЫРЭіВЁР§ЃКаХЯЂзМШЗадНЯВю2ЁЂЖдееЕФбЁдё
ИќИДдгЁЂИќРЇФбЃЁ
бЁдёЪЧЗёЧЁЕБЪЧВЁР§ЖдеебаОПГЩАмЕФЙиМќжЎвЛЃЁ
ЖдеезюКУЪЧШЋШЫШКЕФвЛИіЮоЦЋбљБОЃЌЛђЪЧВњЩњВЁР§ЕФШЫШКжаШЋЬхЗЧЛМИУВЁЕФШЫ
ЕФвЛИіЫцЛњбљБОЃЌЖјЧввВОЙ§ЯрЭЌеяЖЯШЗШЯЮЊВЛЛМЫљбаОПЕФМВВЁ
ИљОнВЁР§ЕФЖЈвхПЩвдШЗЖЈВЁР§ЕФдДШЫШКЃЈsource populationЃЉЃЌЖдеегІЕБДгИУдДШЫШКжаГщШЁ
ЪЕМЪЙЄзїжаЕФЖдееРДдД
ЭЌвЛЛђЖрИівНСЦЛњЙЙжаеяЖЯЕФЦфЫћВЁР§
ВЁР§ЕФСкОгЛђЫљдкЭЌвЛОгЮЏЛсЁЂзЁеЌЧјФкЕФНЁПЕШЫЛђЗЧИУВЁВЁШЫ
ЩчЛсЭХЬхШЫШКжаЕФЗЧИУВЁВЁР§ЛђНЁПЕШЫ
ЩчЧјШЫПкжаЕФЗЧВЁР§ЛђНЁПЕШЫШК
ВЁР§ЕФХфХМЁЂЭЌАћЁЂЧзЦнЁЂЭЌбЇЛђЭЌЪТЕШ
ЕкЮхНк ВЁР§ЖдеебаОПЕФЪ§ОнећРэгыЗжЮі(МЦЫуЬт)
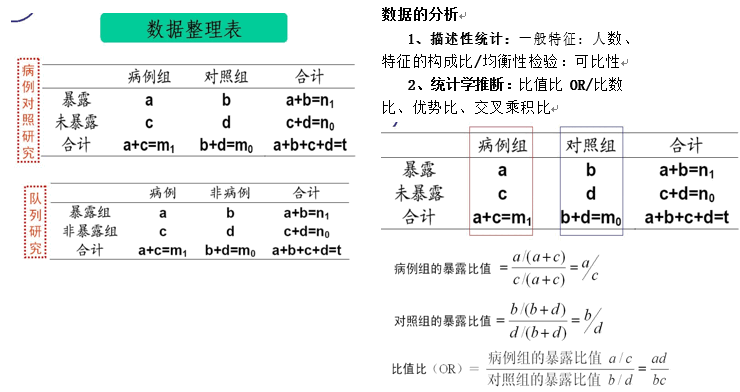
OR ЕФКЌвхгы RR ЯрЭЌЃЌжИБЉТЖзщЕФМВВЁЮЃЯеадЮЊЗЧБЉТЖзщЕФЖрЩйБЖ OR>1 ЫЕУїМВВЁЕФЮЃЯеЖШвђБЉТЖЖјдіМг
